It's Not Google's Fault. It's Yours.
According to a recent Google leak, we’re all to blame for poor quality search results. Summary and thoughts on Rand Fishkin's and Mike King's dropped dual reports on a large-scale leak of Google Search internal documentation for Content API Warehouse.


According to a recent Google leak, we’re all to blame for poor quality search results.
Okay. Right before I headed off to sleep, Rand Fishkin and Mike King dropped dual reports on a large-scale leak of Google Search internal documentation for Content API Warehouse.
So, here we go. Grab a cup of coffee, sit down, and enjoy. I’ll tell you about the key points from the leak on how Google Search works, and then I’ll try to make an argument.
I want to show you that it’s not any search engine’s fault that our search results suck. The internet is getting ruined on a macro level – decay and rot originate from how digital content is monetized and created in the first place.
Google Content API Warehouse leak
TLDR: On May 27, Rand Fishkin (SparkToro, prev. Moz) got access to internal Google API documentation from an anonymous source. The leak includes, in Rand’s words:
“More than 2,500 pages of API documentation containing 14,014 attributes (API features) that appear to come from Google’s internal “Content API Warehouse.” Based on the document’s commit history, this code was uploaded to GitHub on Mar 27, 2024th and not removed until May 7, 2024th.”
This documentation shows us a fair bit about how Google Search seems to behave behind the scenes. When taken together with observations about recent algorithm updates, all the outcry with AI overviews, and revelations from the recent anti-trust suit against Google – this leak gives us a very close look at what makes search tick.
I haven’t had the time to go through the original API docs in detail myself, but I did take a quick look. More importantly, both Rand and legendary technical SEO Mike King have both provided decent overviews and initial analysis for us to start with.
Other Sources
This story is developing, so I can't catch everything. But here's a start:
- Dixon Jones made all 14,000 attributes within the leak searchable on his site.
- Danny Goodwin from Search Engine Land is keeping track with a short summary and key updates.
- Barry Schwartz is also collecting initial reactions and additional context on Search Engine Roundtable.
Part 1 - information we have
We have a bunch of different modules within this API, each one named based mostly on what it does, for example “GoogleApi.ContentWarehouse.V1.Model.KnowledgeAnswersIntentModifiers” - where we are looking at something to do with how Google models search intent modifiers in reviewing search queries and the types of answers it provides.

Within the page we might get an overall summary (like in the screenshot above), then we have a list of attributes within the API (including detailed comments and notes), types of calls, and functions that are applicable to that module.
It’s honestly hard to even grasp how much information is here - what I can say is that the full-text search works pretty well and you can find a lot simply looking up common terms.
Main findings pointed out by Rand and Mike are as follows:
- Google does have an internal measure of something like Domain Authority (“DA”), called “siteAuthority” and appearing within their overall quality signals.
- Click & user activity data from within search and Chrome users is key to search rankings. (Look into “NavBoost”).
- Not all clicks are made equal - Google pays attention to how long someone stays on the page after clicking on a search result. They actively look for which result had the “longest click” from users (longest engagement).
- New domains seem to be put in a sandbox to prevent spam.
- Human rater scores are used for at least certain parts of the search algorithm.
My Findings
I’ve done some very random poking about on my own, and found a couple of interesting bits of information.
1 - How backlinks and link anchors work
Google looks at A LOT of context around links to see which ones are valuable for determining rankings. Mike King already pointed out that trustworthy domains are prioritized, and a link quality score is applied based on where they are coming from.
I’ve also found an attribute that marks domains for spamming too many anchors, and in those situations says they’ll “throw out all but a sampling of them from that domain.” Uh-oh. It seems if Google catches you cheating, they’ll have many a way of giving you at time-out.
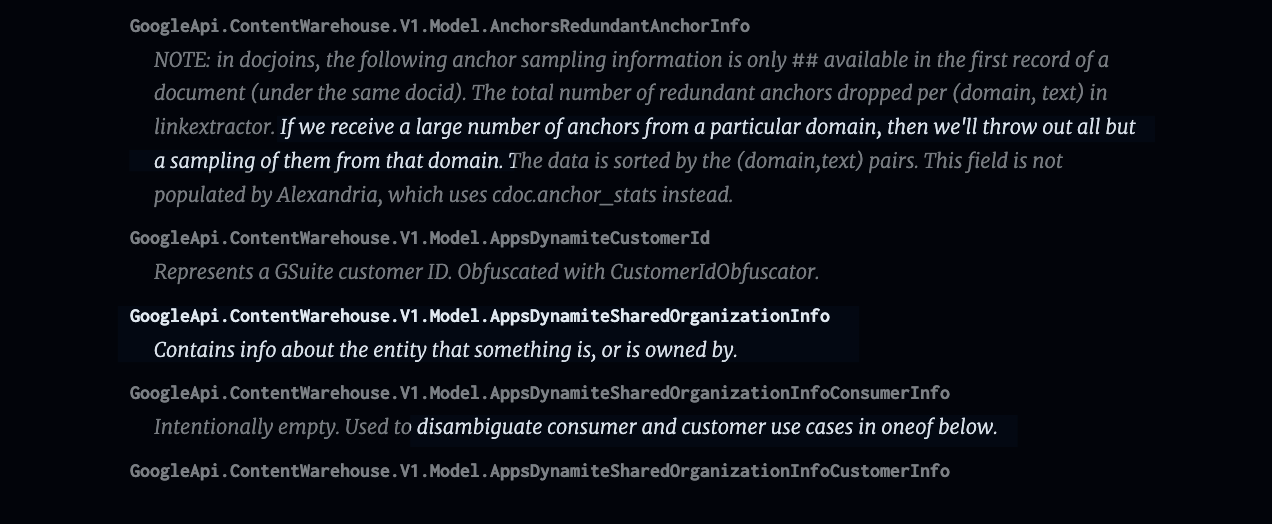
I also found explicit mention of “newsiness” of a link that depends on whether the domain sending links is a “newsy, high quality site”.
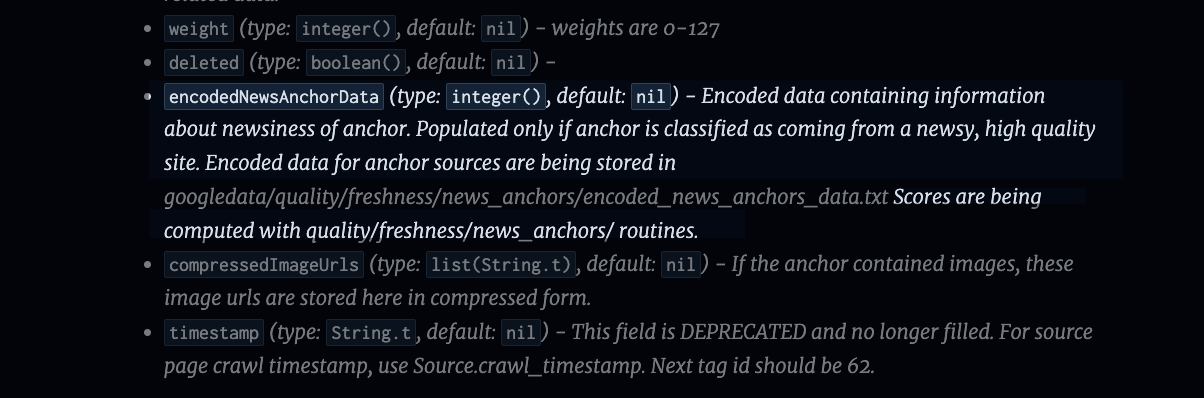
2 - Alexandria
“Alexandria” is mentioned a lot, and seems to be the main indexing system generating data for search. We can see how it works in the output metadata documentation - basically, Google takes most of the information we see when we check page indexing status in Google Search Console - and stores it as a column within their “Alexandria document table”.

Part 2 - information we’re missing
We don’t fully know how updated this information truly is. As Mike found, it seems to be current as of Mar 27, 2024 when it was first uploaded (before getting removed on May 7). However, this could be a backup of outdated systems.
We also don’t have much information of how certain factors are prioritized over others. We have a detailed taxonomy of the kinds of attributes and data points that Google looks at when evaluating search results (including web, YouTube, Books, video search, people API, and more). But we do not have much of the underlying logic beyond what we can infer within the notes and hierarchy being left in this documentation.
We also don’t know how new AI overviews and upcoming search features will change the systems described here.
Part 3 - what this means for SEO
Ranking depends on not simply getting people to click on your site, but attracting “successful clicks” where users stay on your site with great content and a good user experience.
Links need to be diverse and relevant. I saw multiple signals of penalties if one site sends too many links to another particular domain.
Authors, relationships between people and organizations, and local context are all viewed as distinct entities and used within indexing and ranking. Google really does store a fair bit of context and try to approximate how humans earn trust and evaluate one another.
Search intent is… key. Understand what users are looking for, optimize for the users first, and the algorithm should catch up eventually. Similarly to what we saw in the DOJ antitrust trial exhibits, Google cares about three tangible sets of factors:
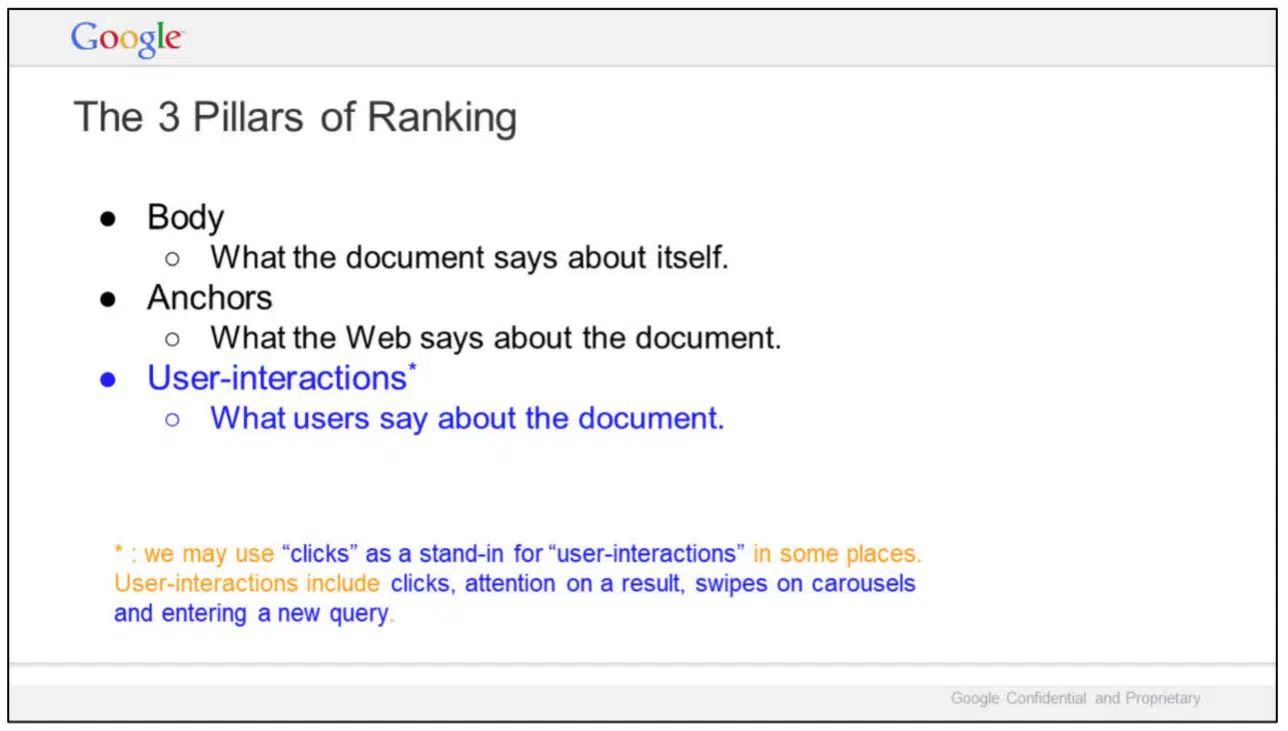
- Specific page and its content
- Connections to other webpages and domains (through anchors)
- User satisfaction and experience.
Understand what the humans want and care about, and you will be able to do much better SEO than if you try to predict the algorithm every step of the way. The algorithm is simply trying to predict and meet human preferences, so you might as well go straight to the source.
Part 4 - what this means for businesses
For search, Google really cares about the quality of:
- Each page and its content
- The overall site and domain that the page is hosted on
- The links and references to the domain and its author from other places on the internet.
Everything I can see so far (and what Mike and Rand summarized) is that Google cares about quality over quantity. It’s better to have a few pages that do really well in rankings, getting users to click and engage with the page, and match user intent. Volume at all costs will simply get your business hit with spam penalties and get Google to prioritize less data about your site.
Our responsibility when helping create or distribute content online
Now, remember that I’m saying we’re all guilty of making search bad?
Well, here’s why:
- Google’s search algorithm is, yet again, shown to depend mostly on what users actually interact with.
- Making good, authoritative, and shareable content is really hard.
- A lot of people and organizations have been trying to make money on the internet.
- When we as marketers, publishers, or businesses fall into the trap of trying to get views / conversions more than genuinely helping users – we flood the internet with crap.
- As we introduce more “bad apples” into the larger content pool, search engines like Google begin to learn from them and even prioritize them in SERP.
Marketing doesn’t exist in a vacuum
When we think about the results of our marketing in a vacuum, we miss the spill-over impact that our bad choices might have over the long-term.
I firmly believe that this kind of “me first” thinking within marketing is damaging the entire web, even when the marketers behind it have good intentions. For example, earlier this month Ryan Law published a piece on Ahrefs titled “Why Big Companies Make Bad Content.”
His thesis is as follows:
“Every published URL and targeted keyword is a new doorway from the backwaters of the internet into your website. It’s a chance to acquire backlinks that wouldn’t otherwise exist, and an opportunity to get your brand in front of thousands of new, otherwise unfamiliar people.”
I understand what Ryan is saying. That perspective is… tempting. Look at all these keywords and SERP listings, ripe for the taking. All of that attention from “new, otherwise unfamiliar people” can be great for your brand, even if you don’t know what to do with it.
The problem is – your business is NOT the only one out there. And when other businesses jump to the same hacks and begin racing to capturing the most eyeballs, all of those beautiful benefits quickly evaporate.
As effective as posting that type of thin content might be for your particular brand, it makes the internet as a whole worse. Think about it: after years of volume-focused content practices from a couple hundred enterprise brands, we’ve now ended up in a world where the concept on niche expertise is non-existent on the SERP.
Do we, as marketers, really want to dedicate years of our lives to building a future where the best source for where to go for brunch in Brooklyn is some financial conglomerate based out of Hong Kong?
Garbage in, garbage out
Imagine that you walk into somebody’s house for the first time. You go up to the second floor, and find yourself in a small home library tucked away in a quiet room.
You look up, and see books beautifully arranged by size, color, and genre. You marvel at how thoughtful the order is, and wonder how long that would have taken to accomplish. Then, you look at the books themselves and realize that they are all printed out transcripts of 80s infomercials about diet supplements.
Bummed out? Yeah, I am too.
Imagine the internet as a very large library. We’re all sharing it, we’re all allowed to add resources to it, and then search engines like Google are librarians – they step in to curate and organize our shelves for easier navigation.
Let’s say that you absolutely LOVE mystery novels. So, you head to our large library and ask the librarian to get you the latest detective story. The librarian nods, types something into their computer, and then turns to say “actually, we don’t have any mystery novels in stock.”
Now, in this situation, who is to blame for your lack of a book fix?
If mystery novels are plentiful and popular in your area but your library doesn’t stock them, the problem is likely the librarian.
If mystery novels don’t get published that often, but they are popular, then the problem is with the publishers for not meeting true market demand.
If mystery novels get printed all the time but they don’t get read at this library and simply gather dust on shelves, then the problem is a mismatch between your taste and your community’s average book preferences.
Any search engine results are just like that library. Whether your results seem relevant or not depends on the search engine (like Google), what content is getting published, and what content is getting most interactions.
Chasing traffic will always bite you
Ryan Law’s piece is a great example of how many marketers do not truly understand marketing theory and focus on tactics rather than connecting their work to the underlying business and market conditions.
The Ahrefs article about “bad content” fundamentally misunderstands:
- Business models and incentives (esp. post-IPO)
- The purpose of brand awareness
- The purpose of share of voice
- Search developments, long-term user expectations impact, and searcher satisfaction
- Overall macro ripple effects from any particular site gobbling up all the traffic and topics
- The purpose of content and of marketing as a whole
- How brand marketing is supposed to function within the larger marketing function.
Ryan writes:
“Companies generally expand their total addressable market (TAM) as they grow, like HubSpot broadening from marketing to sales and customer success, launching new product lines for new—much bigger—audiences. This means the target audience for their content marketing grows alongside.”
It’s a nice idea. It's also idealistic, simplistic, and flat-out wrong.
Your target audience is never going to be the entire planet. No matter what you sell, your marketing needs to be aimed at the people most likely to serve your organization’s strategic goals. Those might not have to be direct customers or leads. They can be partners, content creators with large audiences, investors, potential employees, and more.
The target audience for your content marketing should expand based on when it would most help your entire organization, not when you’ve run out of easy keywords to talk about.
Because of low resulting traffic quality, any keyword swarming strategy truly works only if your business model depends on PPC ads and affiliate links within your site content.
I have a theory based on Google's actions the last 2 years that they are trying to kill the abuse of affiliate ads as a monetization channel - because it's simply gone too far. The aftermath of those decisions means all of us now have to tolerate terrible affiliate sites, backlink farms, drop-shipping, bad UX, lack of journalistic integrity, and continuing reduction in ROI potential for actual advertisers.
Too many sites and businesses out there have decided that the best way to make money from content is to use their traffic as free real estate for willing buyers. Every large company has essentially turned into an influencer, selling ad space within their blogs.
But that ignores the issues that come with needing to monetize content directly, rather than the entire point of content marketing - that good content can help sell your key business products and services indirectly.
Content shouldn't be turned into an e-commerce play by every single site. Content needs to be, at its core, a brand marketing and education play.
We need better marketing education
Our old way of advertising online doesn't work.
A lot of this comes down to a fundamental misunderstanding of the value of content, the purpose of marketing, and why blogging should exist in the first place.
But why are marketers making this many mistakes? Because we weren't educated the right way.
Too many marketers still treat content as window dressing for shoving ads down an audience's throats. Instead, content is a vehicle towards building trust, attracting more qualified leads, and improving other marketing outcomes.
The real problem is education. Marketers don't understand business fundamentals or how their field can truly intersect with other business functions and deliver value both over the short-term and over the long-term.
As Philip Kotler writes in a 2020 piece for Journal of Creating Value:
“Leading marketers see modern marketing to be all about value creation. Marketing aims to meet human needs by creating value. The marketer chooses the product features and services that will deliver value. The marketer chooses prices that will create value in exchange. The marketer chooses channels of distribution that create accessibility and convenience value. The marketer chooses messages that describe the value their offerings create. I do not know what you thought marketing was, but in my mind, marketing is intrinsically a value-creating discipline.”
Marketing is a lot more expansive than ads or growth hacks. Marketing is about influence, and that always has ripple effects across business functions.
We’re using the wrong economics for content
Content on modern websites is often playing a supporting role to where the real money is made - affiliate advertising.
Unfortunately, affiliate links are kind of terrible. I’d even say that affiliate links are the marketing equivalent of private equity at its worst.
Organizations focused on affiliate revenue tend to damage the businesses they touch a lot more than they help them. Much like bad PE firms affiliate networks are frequently dismantling reputable sides, destroying long-term business potential, and turning everything page into filler content assets to be picked apart. Then those faceless pages are sold on the digital market to the most willing buyer, before scampering off with the spoils and letting resulting ruins of once great content rot in obscurity. (Or simply scrapping it for parts.)
When private equity damages the business under its ownership, the reasons tend to boil down to the following:
- Lack of understanding of the core business model.
- Narrow definition of "value”.
- Blinding focus on short-term gains with zero regard for long-term losses.
- Lack of attention to macro effects.
Unfortunately I see all of those mistakes with ad-addicted or affiliate-reliant content programs.
Asset Classes
Okay, if we are talking about economic value, let’s get our definitions cleared up. Here are some key asset classes within modern digital content:
- PPC ads
- Affiliate links
- Backlinks
- Traffic / reputation with domain name
- Data (cookies, visitor tracking).
And not all of those assets are equally valuable or risky.
For example, I think that ads and content are frequently misunderstood:
- Paid ads are a commodity. It's like grain - quick to move, you can count on being able to sell it. Seems like it's probably a safe business to get into. Very liquid.
- Good content is like real estate. Real estate is valuable even if the business that is operating within a building at that time might actually be actively bleeding money (like hotels or restaurants). The real asset is its location, especially long-term. A location that's pleasant to be in is valuable.
And frankly, we need to stop pitting paid ads against content because one is a commodity asset, while the other is an illiquid long-term investment.
Reassessing the role of content
In too many organizations, content gets seen as a liquid stock (at its worst, a day-traded short stock), but in reality it should be understood like investment in illiquid real-estate.
To use a stronger comparison - in many organizations content is being used as a money-laundering front for a web of ad, backlink, and affiliate networks.
And those networks aren’t necessarily evil, nefarious, or secret. If you’ve ever paid for a backlink from a specialized vendor - you’ve invested money into one of them. But the reason it happens is quite simple.
Businesses are often stuck in the mindset of “just publish something, anything, we need to make it look like there’s actual legitimate business activity going on”. However, when there is no solid business justification behind that activity, it will never be as affective as a more strategic investment.
When traffic and clicks becomes “buzz” and “hype” and used to convince investors that the business underneath is actually valuable.
The entire house of cards that produces cheap content depends on the promise and assumption of infinite traffic growth and an infinite supply of available attention. Both of which have long since ceased to be true.
What it means to build trust online
Google’s core updates since the Helpful Content Update (HCU) have approximated a model of “who is trustworthy” based on 3 main factors:
- Content - what are they saying and how are they saying it? (Substance)
- Consistency - how much have they said this before, how often do they talk about this and similar concepts? (Experience)
- Credibility - who else trusts them and who is affiliated with them? (Connections / collaborators / citations)
This framework is similar to EEAT, but I think it’s a bit more natural to how we as humans assess what people or organizations we can trust. And as Google gets more sophisticated with its ability to create people and organization entities with contextual data, the SERP can also improve in approximating trust.
Let your marketing be more creative
Some companies know how to attract their audience and make great content, but they can't figure out how to be found by people on search. Distribution isn’t built into their content creation process, and adding it as an afterthought can be quite difficult.
Other companies know how to attract traffic through search, but their content can sometimes be too basic and flat. Too many SEO programs and SEO tools think about search marketing too directly - targeting search terms that match their exact terms and direct product descriptions.
Then, too many terrible SEO programs just take direct linguistic matches as keywords and don't think on how to expand it.
Both a branded piece with 0 search traffic and your typical bad SEO listicle are on opposite sides of the same spectrum. The former group understands their audience, but not how to connect it to search; the latter group understands what people search for, but not how to serve the audience.
Good SEO is in the middle - it has both. Successful SEO needs to both speak the language of the search engine and understand the audience and their psychological needs.
This is actually why I think SparkToro and some of Semrush's newer tools are so valuable - these tools help us figure out what people search for outside of the obvious or direct terminology.
Too many companies rely on the basic exact category names, product descriptions, and verticals. That approach lacks imagination.
What is the wider circle of terms adjacent to a company's product or service offering that does get searched for? How can you start that journey of getting people acquainted with your brand?
Final words: remember your culpability
Yeah, we’re all kind of guilty of making the internet worse. But that doesn’t mean everything is doomed - by truly focusing on the user, building trust, and reaching the right people on subjects our organizations can reputably talk about - we can begin to improve the quality of average search results for everyone.
And when search engines have better pages to pick from, improving the SERP gets all that much easier.